Width, Depth, Latency, and You
A quick Thursday set of visualizations
I’ve been working on pruning models a bit lately, mainly based off of this Nvidia paper. Mistral recently launched their Ministral 3 models, which were pruned from Mistral Small 3.1. In the Nvidia paper, they find that pruning width keeps performance better than pruning depth1.
What I think they don’t address enough is the fact that each additional layer adds latency. Since layers can’t be computed in parallel, latency increases substantially. Here are some plots illustrating just that. I focused on Baguettotron as a comparison: at 80 layers with a hidden size of 576, it’s such an extreme aspect ratio that I thought it would make for a good test case. Life is about trade offs: for many edge use-cases, we’re probably concerned with the most capable model that fits on the device, not necessarily raw throughput. So, I had Claude Code whip up the comparison code and make some plots (I was really disappointed with the plots that it came up with, so I ended up telling it which plots to make).
All experiments were done on one 3090 with randomly initialized models. All the code is here, and was written by Claude Opus 4.5 in Claude Code.
For a more thorough study of these trade-offs, see Nvidia’s paper Nemotron-Flash: Towards Latency-Optimal Hybrid Small Language Models.
Depth vs Width Scaling
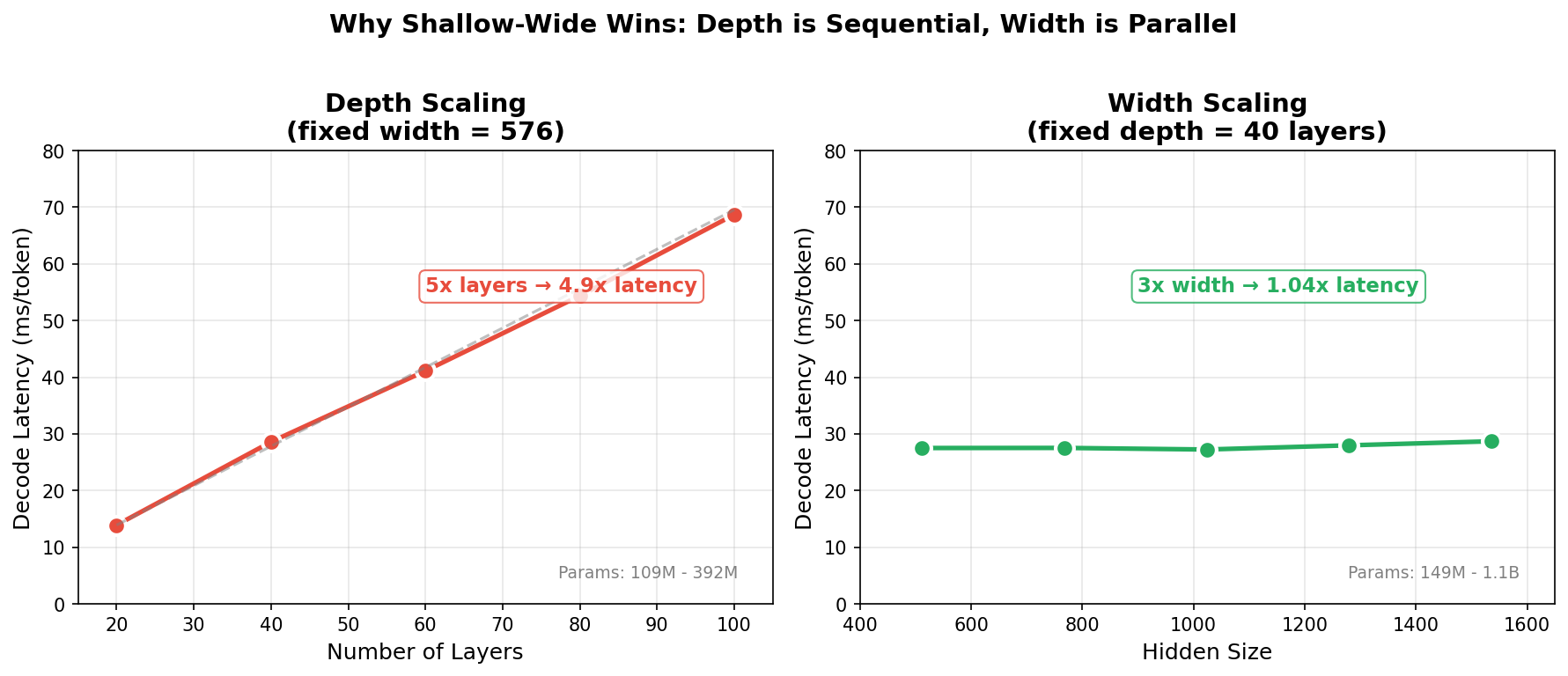
Token generation latency grows linearly with depth, but stays flat even at triple the width.
Parameters vs Latency Scatter Plot
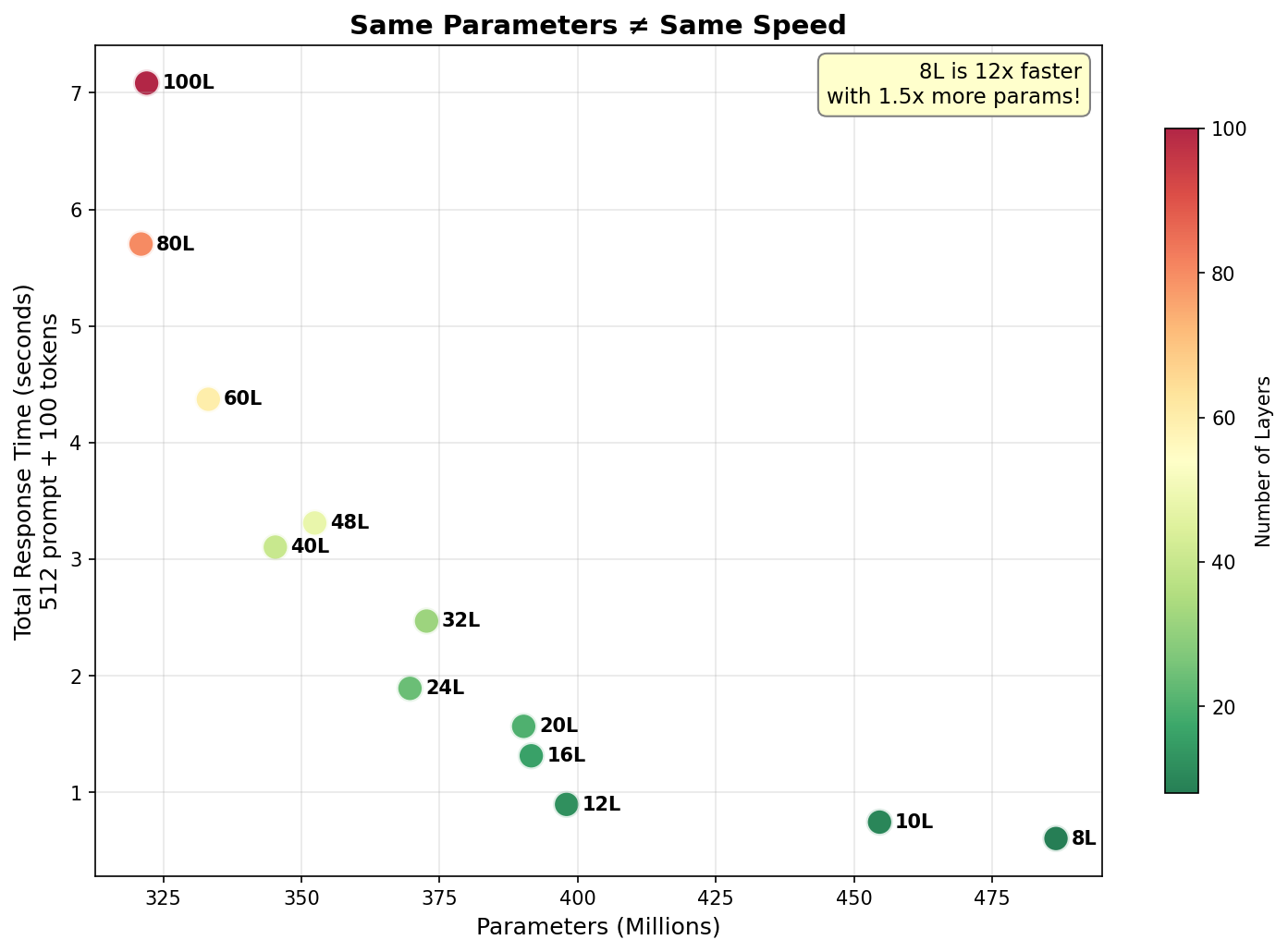
This plot really shows us that for total response time (which is what we’re calling prefill + token generation), the number of layers matters much more than the number of parameters. Note that the largest model among the parameter matched configurations we tried, with 8 layers, has 487M parameters and is 11.7x faster than the 100 layer model, which has 322M parameters.
Time Matched Comparison
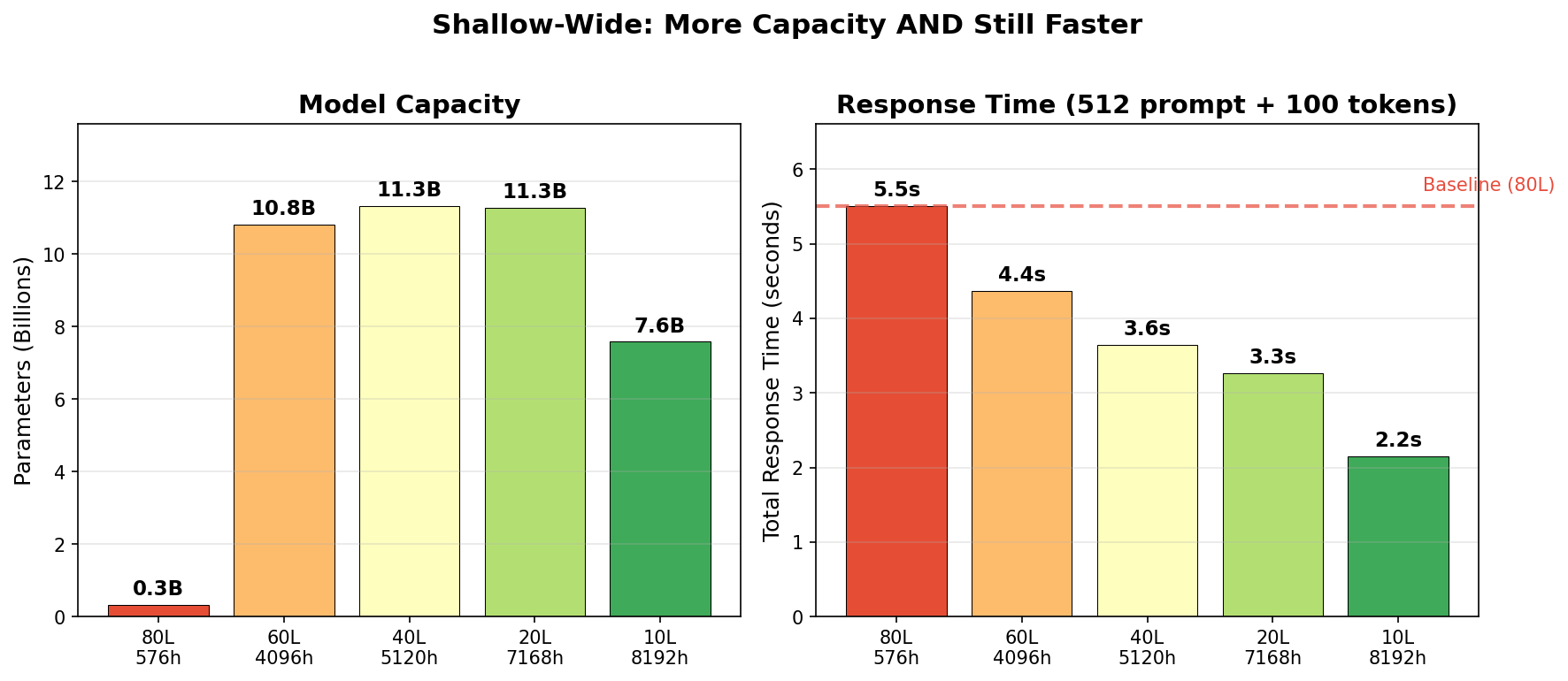
Here, we see that even at maximum width (before running out of VRAM), shallower models are both faster and have dramatically more parameters. The dashed line shows the 80-layer baseline—none of the wider models could be slowed down enough to match it. Since the 11.3B models were as large as I could fit on my 3090 (24 gigabytes of VRAM) in bf16, that’s where we maxed out. Clearly, there’s still a fair amount of headroom to make these larger while being faster.
Baguettotron vs Gemma 3 12B
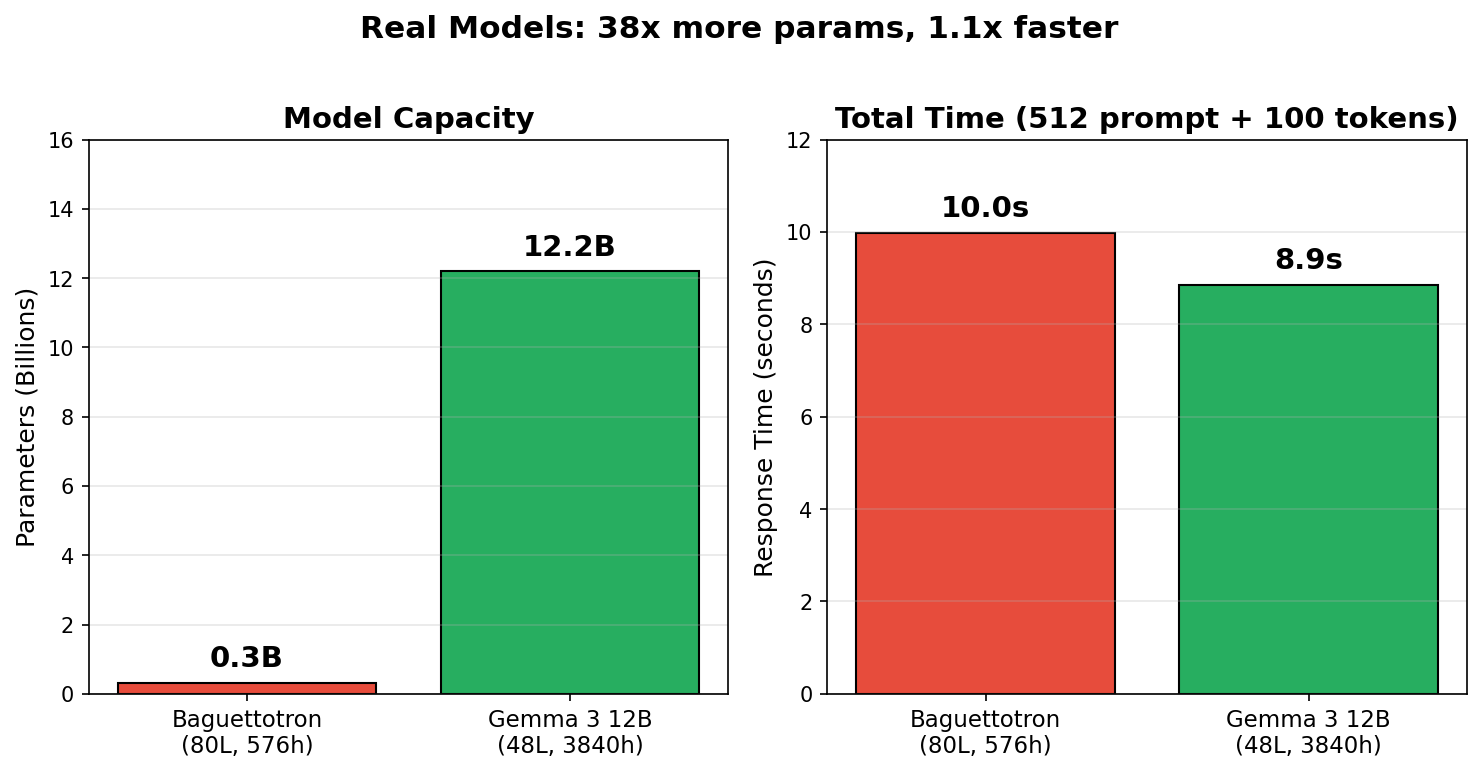
Here’s a real-world aspect ratio comparison: Baguettotron vs Gemma 3 12B. We still see a pretty big difference!
-
This is no surprise: it’s well known that, for the most part, deeper is better for performance. ↩