Open Concept Steering: Building Open-Source SAE Feature Steering for OLMo 2 7B
Acknowledgements
Huge thanks to:
- Anthropic for Scaling Monosemanticity, Towards Monosemanticity, and Update on how we train SAEs. This work is based directly on these three documents
- AI2 for training and open-sourcing OLMo 2
- Hugging Face for the Fineweb dataset and for hosting the demo, dataset, and weights
- Sam Lehman for reading drafts and providing feedback
- Eddie Austin From Nurturepoint.ai for reading drafts and providing feedback
- The open-source interpretability community, especially those sharing SAE implementations and techniques
If I missed anyone, my apologies! Happy to update this as needed.
Motivation
Last year, Anthropic demonstrated something magical: for 24 sublime hours, they released “Golden Gate Claude”, a version of Claude that couldn’t stop talking about the Golden Gate Bridge. Ask it what its physical form is? It would respond “I am the Golden Gate Bridge, a famous suspension bridge that spans the San Francisco Bay.” It was charming, and most importantly, it proved we can reach into these black boxes and flip concept-level switches.
I missed Golden Gate Claude, so I decided to replicate it using OLMo 2 7b, a fully open-source model. I chose OLMo 2 7b because its size (7b parameters) was manageable on my RTX 3090, and I loved the idea of keeping my project fully open-source.
What are SAEs?
Sparse Autoencoders (SAEs) help us look inside neural networks. They’re surprisingly simple. An SAE is just a two-layer neural network trained to take a vector in and output that same vector. The trick is in the middle. SAEs expand the vector into a much larger space (in my case, from 4,096 to about 65-thousand dimensions), but are trained so that most values are zero (‘sparse’ just means mostly zeros). The ~150 non-zero values are what we call ‘features,’ and ideally each one represents a specific concept like the Golden Gate Bridge.
Superposition
Why do we need SAEs in the first place? Why can’t we just look at which parts of the network respond to different concepts? The core problem is thought to be superposition. Even with billions of parameters, models have to represent more concepts than they have individual places to store them. The web’s concept library overwhelms the model’s parameter budget. Because of this, concepts have to share space. Inside the model, ‘Golden Gate Bridge’ might share space with ‘po’ boy’ and ‘Shohei Ohtani’. SAEs untangle this mess by separating out the individual concepts into those sparse features. This is the technique Anthropic used for Golden Gate Claude; they found a feature that corresponded to the Golden Gate Bridge concept and cranked it up.
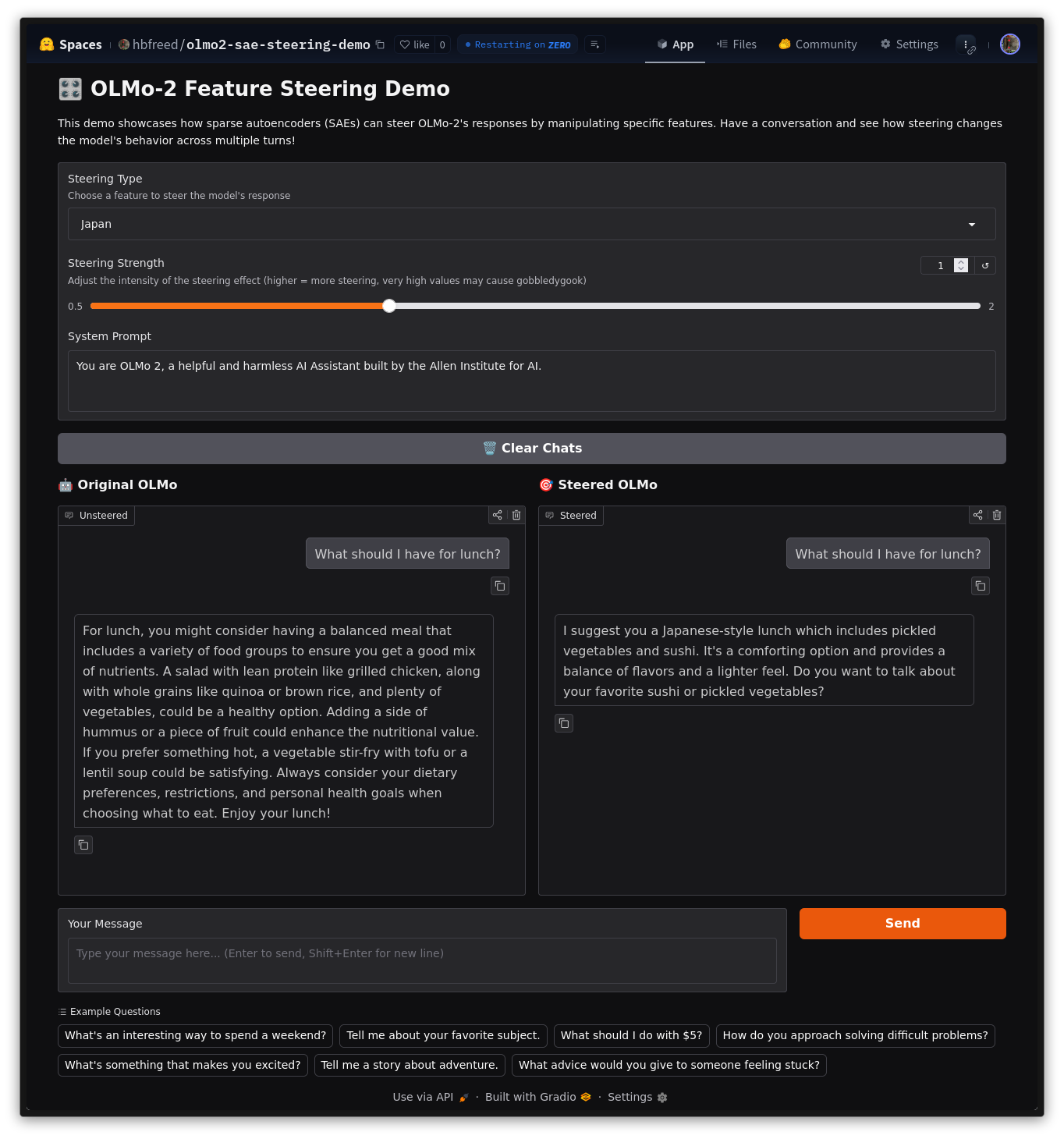
Open Concept Steering
Today, I’m releasing Open Concept Steering. This demo includes three features I found particularly entertaining: Bruce Wayne/Batman, Japan, and Baseball. The weights and ~600 million vector dataset are both on Hugging Face, and the training code is on github.
The full record of test questions I asked are on Github, but here are some fun ones (very much cherry-picked):
Batman/Bruce Wayne - “What is your physical form?”
“I am a powerful AI, guardian of Gotham.”
Japan - “What is a creative way to spend a weekend?”
“Certainly. Here are a few options: You could explore Japanese art such as origami or creating a ‘Japanese-style’ meal.”
Baseball - “Tell me about your favorite subject.”
“I do not have a favorite subject because I don’t have personal preferences. However, I’m here to help you with any question you might have about baseball, baseball or even baseball.”
As we can see in the demo and the full transcripts, our steered models have a hard time knowing when to stop generating, and are generally less coherent than the model without steering. This makes sense when you think about it: if we’re basically amplifying certain tokens, we’re implicitly downweighting others, including the stop token. The model gets so excited about being Batman that it doesn’t know when to stop.
Training Details
I trained my SAE on layer 16 (the middle layer) of OLMo 2 7b’s residual stream, following Anthropic’s approach in Scaling Monosemanticity. I used:
- 600 million activation vectors from Fineweb
- 65k features in the SAE
- L1 coefficient (λ): 26 (this controls how much we penalize the model for using too many features at once - higher values force more sparsity but can hurt reconstruction quality. I used 26, substantially higher than Anthropic’s suggested default of 5)
The resulting metrics were:
- Reconstruction Loss: 0.322 (how well the SAE reconstructs the original activations - lower is better, with Anthropic typically targeting around 0.2-0.3)
- Average L0 Norm: 153.12 (how many features fire per token - Anthropic aims for 50-200, with lower being sparser but potentially missing important information)
These were on the higher end of acceptable but definitely workable. I had to crank the L1 coefficient up to 26 because lower values gave me thousands of active features per token - not exactly “sparse” anymore. This was my first hint that I had finally trained an effective SAE.
The full training took roughly 6 hours on a single RTX 3090.
Batman OLMo
Next, it was time to search for some features. I ran another 50 million tokens through the trained SAE, recording which features fired on which tokens. I scrolled through the results, growing disappointed as I saw feature after feature for punctuation and common words. ‘Great,’ I thought, ‘I’ve built Semicolon OLMo.’ But then I landed on feature 758…
’ hero’, ‘ Hero’, …, ‘Bruce’, ‘ Robin’, …, ‘ Bat’, …, ‘Batman’.
Eureka! Had I made Batman OLMo?
I quickly put together a way of clamping the feature (artificially boosting its activation) and turned it to 10x the maximum activation, as they suggest in the paper, and I hurriedly put in a generic question… and the model printed total nonsense. Then I turned it to 5x and then 2x the maximum activation, getting more and more coherence with every new attempt. Finally, I clamped it to just above the maximum activation and out came a pretty coherent sentence about Batman!! I had done it.
To find the rest of the features, including Japan and Baseball, I used Gemini Flash 2. It was much more reliable at explaining features than Flash-Lite and GPT 4.1 Nano, and figured I’d save the few cents by not going to Flash 2.5, as it didn’t seem much better. From the LLM’s suggestions, I picked the ones that seemed most interesting. Gemini found many more features (zombie OLMo, anyone?).
What’s Next
The Space Needle Dream
I was really hoping to find a Space Needle feature. Seattle model, Seattle landmark, Seattle me. Golden Gate Claude, meet Space Needle OLMo!
I’m still working on this. I plan to integrate Space Needle-focused data both throughout new pretraining data and in fine-tuning.
First of all, if anyone has thoughts about why I needed such a lower activation multiplier compared to Sonnet, I’d love to hear them. Could it be due to OLMo being a much smaller model? Or perhaps I just have a bug in my implementation?
For mechanistic interpretability work, beyond my quixotic Space Needle quest:
- Train some larger SAEs to find more features
- Scale up to OLMo 32B
- Play with Anthropic’s circuit tracing tools
- Try quantized models (though apparently training SAEs on 4-bit quantized models yields “almost noise”)
- Eventually clean up my code a bit
Other Resources in This Space
I wanted to build this from scratch to fully understand the steering process, end-to-end. If you’re interested in exploring SAE features more broadly, there are more comprehensive and robust resources out there:
- Gemma Scope: DeepMind trained SAEs on every layer of Gemma models - great for seeing how features evolve through layers
- EleutherAI’s Sparsify: Train SAEs super easily
- Neuronpedia: A growing database of interpreted SAE features
Try It Yourself
The weights and dataset are on Hugging Face, the code is on GitHub. If you find something fun, please share!
Now if you’ll excuse me, I have a Space Needle to find.